Chip power consumption "shocking"
"The single-training cluster scale for large language models (LLMs) rapidly evolved from the thousand-card scale (GPT-3, Llama-2) in 2023 to the ten-thousand-card scale (Llama-3), and even to the hundred-thousand-card scale (xAI, GPT-5)."
"The power consumption of single chips is growing rapidly, and we cannot place over 100,000 H100 chips in the same state for GPT-6 training, otherwise it will lead to a grid collapse."

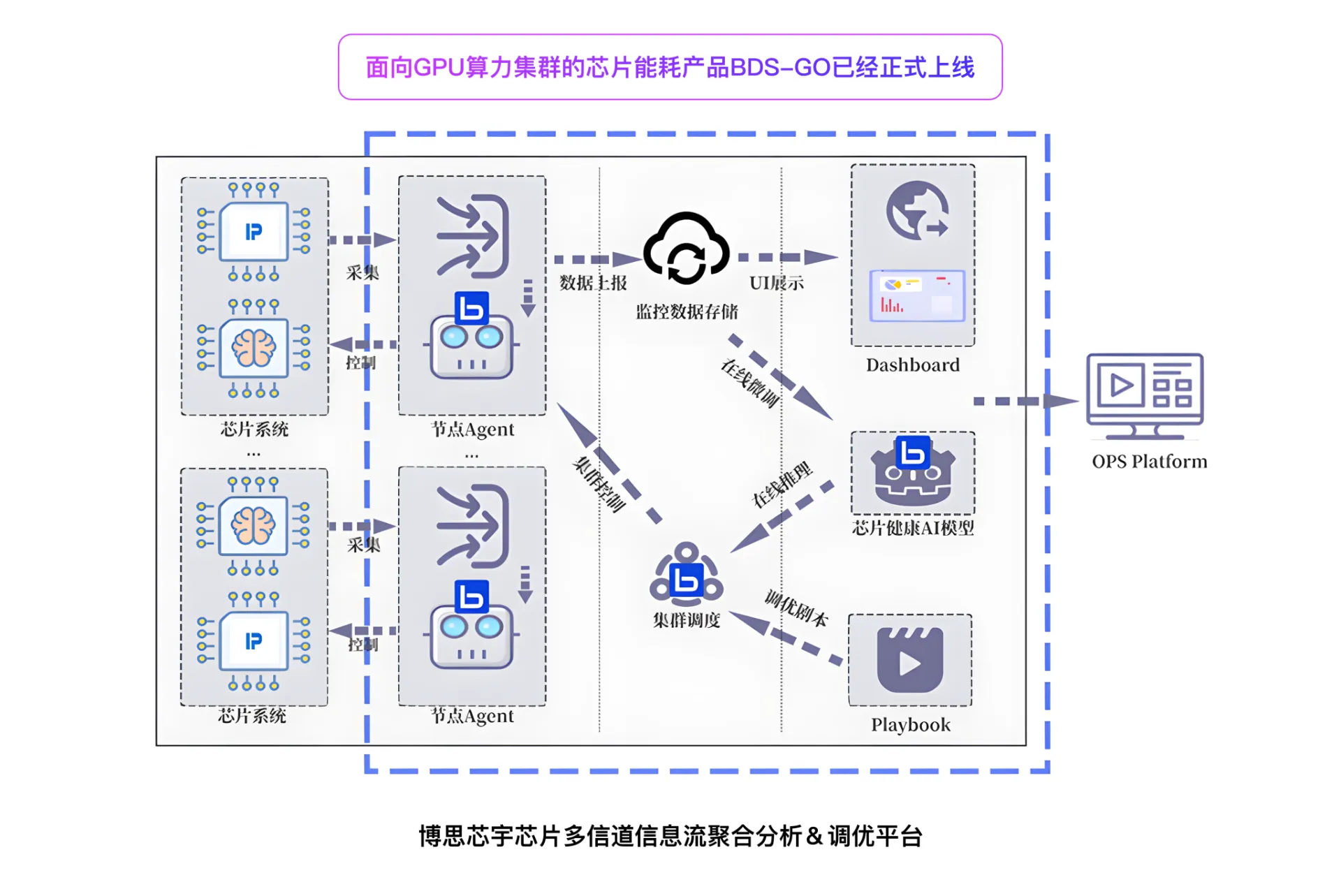
Therefore, the advantages of our platform
BDS-GO: Reduce chip energy consumption
On average, every 100 units of 8-card Nvidia H100 computing power servers
On average, every 100 units of 8-card Nvidia H100 computing power servers




BDS-GO: Core Temperature Decrease
Reduce GPU core temperature: Reduce the cooling pressure of devices such as liquid cooling and air conditioning, effectively lowering The overall PUE of the data center effectively delays chip aging and ensures the performance of chips at the end of their service life Prevent chips from dropping frequencies or cards due to high temperatures, and reduce operational pressure